
the human intelligence blueprint
schizoposting about how to build next-gen AI

the paperclip maximizer was a midwit thought exercise, just like the trolley problem or the Turing test. practically useless AI pop science. of course those with a differentiated thinking function need to be moved by some synthetically constructed thought experiment that is far enough to reach they can't rationally collapse it immediately. anyone though, with a developed sense of ML intuition, may immediately see how superficial those cuts are in the hyperspace of possible AGI. in hindsight, i can be cheeky about this, because i never gasped at anything e.g. Nick Bostrom the philosopher guy had to say—though he did explore whole brain emulation quite well back in 2008 (!) when i was mostly occupied with wanking myself off and playing Battlefield 2, so yeah, credit where it's due.
AI doomers, woke AI research censors and ethics committees will come and go with close to no input to the field other than hindering progress. as the necessary software and hardware components—the soil from which general intelligence should emerge—has been shifting quite viciously even in the last few years, the only thing we are left with, after endless circle jerking and attention-grabbing convos, are doomer fantasies built on deprecated assumptions and groundless ethical claims and guardrails no one in their right mind will ever comply with.
Eliezer, where the fuck are you now?
naturally, this is not to say there is no place for ethical considerations in AI; what i simply mean is that most are annoyingly stupid with an undeserved moral aura. trusting in the ‘50% of researchers’ that assign a ≥10% chance of AI-brought human extinction, 0% of whom have developed AGI in actuality, is a wild argument. watching the Terminator series biases one more than years of ML experience. the last major leap in AI—feeding massive text corpora to self-supervised transformers—was not on the bingo card of most engineers.
let me rant a little more and get some popular AGI theories out of the way:
the “just feed more data”: co-staring “just feed more modality”; sure, but i doubt this will get us to autonomous intelligence.
the “just put it in a body”—i like this one: complex intelligence can only be fostered in a complex environment, performing actions and observing the outcome, i.e. build world models. still, this alone doesn’t give you sample efficiency or generalization on par with humans.
Gary Marcus’s neuro-symbolic AI: aka just add symbolic manipulation to DL, we don’t really know how at scale, other than discrete tokenization of input/output, which gets you halfway there. i don’t like Gary, he’s a reactionary jackass; and i don’t think discarding this theory requires more explanation other than an ad hominem.
LeCun’s autonomous machine intelligence: il build a wholly differentiable system of arbitrary modules, but don’t worry le professeur will rationalize each piece and manages to sneak in his joint embedding obsession to create a Frankenstein AGI—a half-assed attempt. btw i think the direction of predicting latent representations instead of focusing on reconstruction is well-founded and it mirrors the neuroscientific theory of predictive coding. but then there’s NEPA that just does this without all the complexity JEPAs require in a predictive autoregressive setting. LeCun has a grudge against LLMs and autoregressive prediction, and it blinds him.
agentic LLMs with advanced context engineering: or whatever this is and the like. maxing out LLMs has practical benefits, but it will only yield incremental improvements and models ungrounded from reality.
i've been using AGI, human-level intelligence and other designations interchangeably. the reason being is that i don't give a flying fuck how we call the next best AI. no one really knows how to do a logarithmic jump from LLMs to gain more intelligence, continual learning, autonomy, generalizability, sample efficiency, alignment, or hallucination-free models. i also doubt that specifically engineering solutions for each of these would really give you anything worthwhile. so what would?
Sutskever's three
in my view, out of today's mainstream researchers, there is one with the most experience in making intelligence systems without a strong bias. in a recent podcast, Ilya alluded to his approximate research directions towards AGI. he’s focusing on continual learning, sample efficiency ≃ generalizability, and robust alignment ≃ ‘an intrinsic care for sentient life’. his goal is a human-like agent that can generalize across tasks, as such, learn novel tasks fast, incrementally building its knowledge base, while acting on empathy, having compassion towards living beings, employing some mirror-neuron like mechanisms.

these building blocks make sense. the most intelligent autonomous model we know of is human, so let's imitate that on silicon. in fact, i doubt we could build anything alien first (for reasons i describe below). guess-engineering AGI without taking inspiration from the human brain and betting it will work is pure wishful thinking.
out of Ilya’s building blocks there seem to be an odd one out: empathy. he says:
“I think [empathy is] an emergent property from the fact that we model others with the same circuit that we use to model ourselves, because that’s the most efficient thing to do.”
empathy would not just be 'forced' on a potential AGI model to function as a leash. it is a modeling directive—it enables efficient modeling of the world around us, accurately simulating other sentients, creating a compressed inner world, where we live their experiences on the same neural computational support as we live our own. we evolved to simulate, imitate others in the same neural computational substrate that realizes our own life experiences, because evolutionary constraints spared cognitive resources, and because forward predicting the future states of the world, and how our actions influence it, has been the most effective and scalable method for survival. in other words, empathy evolved as a mechanism for social prediction. here’s my prev post for more, about the depth psychology side of things, involving archetypal compression and emulation of others.
i do believe Ilya is the closest to pull off (safe) general intelligence. i also believe that neuroscience and depth psychology are key to the solution. concretely, the intersection of high dimensional modeling (computer science, ML), neuroscience and depth psychology, at their current state, should contain the necessary ingredients for brewing human-like intelligence. well, let’s see how…
the blueprint
the recipe: topology + objective + xp → general intelligence.
to conquer sample-efficiency, generalizability and continual learning in one swoop, we need adequate neural model architectures, i.e. neural topology maps. we are poised to derive such maps from whole brain imaging of mammals and humans, and from nowhere else at sufficient scale. the objective/loss/reward function can be derived from neuroscientific theories of predictive coding and active inference, and it is forward prediction at its core. to train the above, active experience data need to be gathered from real, or generated from virtual environments. models are trained either online in closed-loop, or offline in an imitation-like setting.
topological scarcity
network topology is the principal component governing deep learning model performance. optimizers may be swapped, dropout and normalization layers may be shifted around, tricks like weight decay, parameter initialization schemes and noise injection being present or absent, none influence the resulting performance as much as topology. training may diverge or become painfully slow in the absence of any of the above, but their necessity, in the first place, is determined by topology.
we have discovered effective topologies like what: feedforward, convolutional, gated recurrence, attention, residuals, message-passing, modulation, encoder-decoders, quantized bottlenecks, external memory, conditional routing. seriously, is that it?
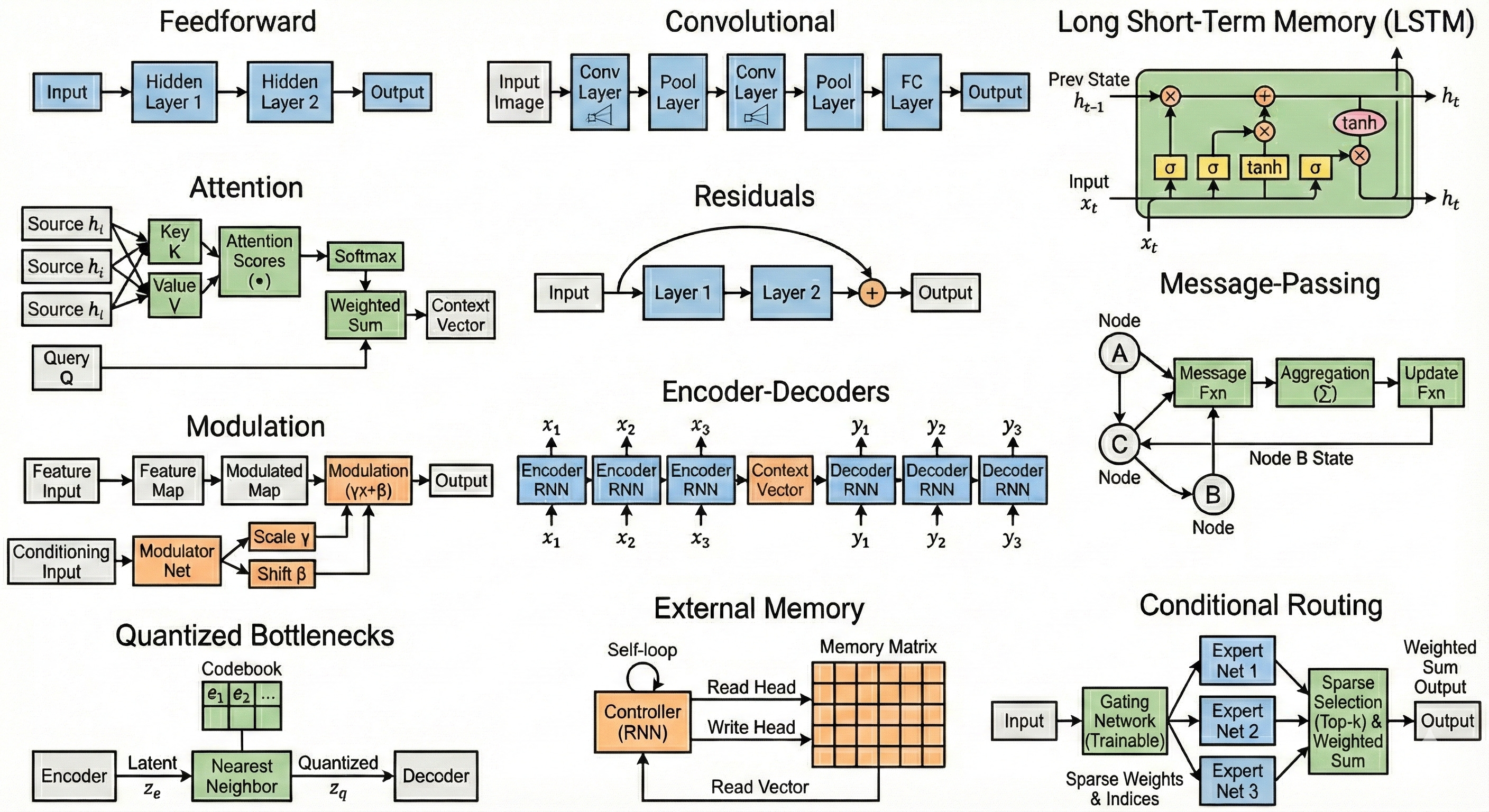
decades of engineering work needs to be humbled by the diversity of effective topologies present in biological neural circuits. my point is: topological space is so enormous, and potent instances are so sparse, we have no chance to discover the sample efficient, generalizing ones through the scientific method. nor will we Neural Architecture Search such a large space. biological evolution did the work already; why not just extract topologies from brains and improve and scale them?
because doing so at the sufficient single-cell resolution has been insanely expensive. the MICrONS project, scanning, segmenting and manually post-editing 1 mm3 of mouse visual cortex costed $100M (though this included functional experiments and other items too). they scanned the tissue with electron microscopes, generated 2 PB raw data consisting of 95M tiles, stitched and segmented the volume, then made over 1M manual edits (~40 person-years worth of labor) to fix segmentation errors. a whole mouse brain is 500 mm3, humans pack 1200 cm3, do the math.
the above mentioned MICrONS dataset was acquired and processed between 2016-2021. since then, connectomics has come a long way. expansion microscopy enlarges tissue by 10–20×, enabling light microscopes to image at sufficient resolution to segment neurons accurately and detect synapses, leading to much faster and cheaper imaging than with electron microscopes. though segmentation at scale is still not plug-and-play (i'm working on a pipeline rn at eon.systems), there has been software developed in labs to pick and choose from. automated proof-reading is not solved yet either, check out this cool approach tho. the cost is lower by about 2–3 orders of magnitude compared to 2021.

even scanning the full connectome of a single mouse or human could deliver lots of neural network topologies to experiment with. although i'm very confident here in the transference and effectiveness of biological neural topologies, there's not an abundance of proof in the literature.
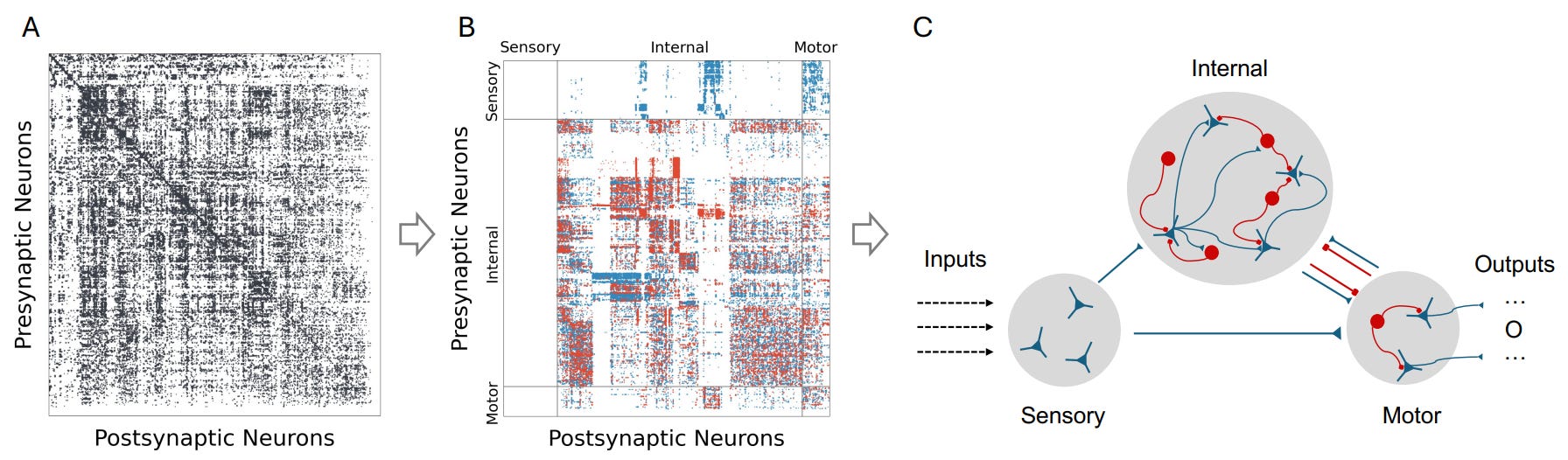
Yu et al. translated a Drosophila larval connectome into a sparsely connected recurrent neural net, initialized the RNN connectivity weights from synaptic counts (↑ synapses → ↑ weight), and set the sign of the weights from classifying neuron types beforehand (excitatory → +, inhibitory → −). they froze the RNN and only trained task-specific encoder and decoder layers attached to it. as such, each neuron’s state was defined by a scalar, two neurons were connected if they shared synapses in the source connectome. MLPs and transformers of the same and larger sizes were compared to the connectome-inspired RNN. tasks were: MNIST and CIFAR-10 classification, and ChestBench. all kinds of trickery are going on in this paper: how they crippled the control MLP, or helped the connectome RNN with minimax search to solve chess puzzles. still, the results suggest that the biological topology outperforms (↑ accuracy, ↑ sample efficiency) vanilla DL architectures of the same size in tasks that a larval brain had hardly been evolutionary optimized for. it subtly points to the importance of topology and its generalization. they also introduce structured connectomics expansion, a principled way to scale the extracted connectome while preserving its block-level wiring statistics.
in the flyGNN project, they instantiate a graph neural net from the adult Drosophila connectome, simulate the 3D fly movement in MuJoCo, and make it walk, turn and fly. here, the GNN weights are not frozen, and are trained together with input/output encoders/decoders in an imitation setting (supervised observation → action mapping), and then RL fine-tuned (PPO), where the weights are updated live as the fly moves in the virtual environment. cool paper, shows that we can train and embody a biological topology.
the work of Costi et al. further shows that biological connectome topology and weight structure yield more robust generalization than random reservoir models. albeit, this result holds within a specific modeling regime1, and the random control is not particularly strong.
across these papers, we see consistent—if modest—evidence that topology improves both sample efficiency and generalization. the exact implementation and biological plausibility of neurons may not matter quite as much; we might be able to do without extracting structure beyond connectivity: e.g. no need to map mechanistically faithful neurotransmitter chemistry or membrane dynamics to see benefits in artificial neural network design. due to the connectomic redundancy we see in the brain, we might not even need super accurate segmentation, so expensive manual post-editing may be avoided. whole human brain emulation is a separate problem somewhat, likely requiring higher accuracy and biological fidelity.
active inference as objective
gonna give you an LLM distilled definition of active inference: "This unified framework explains perception as minimizing prediction error through belief updating, action as minimizing error through environmental sampling, and learning as minimizing error through parameter updates". in simpler terms: we act to make what happens next less surprising. predictive coding is just a passive version of active inference, where the brain at time t predicts the to be percepted input of t+1, and with neural message passing minimizes the occurring predictive error. thus predictive coding models the brain as a next state predictor, and from that, most behavioral, psychological and neuroscientific phenomenon, including consciousness, ofc, to an extent, ofc, can be explained. in another post, i described why i believe future state prediction ≈ world models ≈ inner simulation of the outer world is at the core of psychic functions, and that most if not all neurosis can be traced back to faulty predictions = mismatch between reality and the internalized world model.
learning is by large local in the brain. dopamine-based RL feedback may be considered as a more global modulatory signal influencing synaptic updates, but the rest is local and is performed between cortical layers2. predictive coding theory says that the local loss is prediction error. across cortical layers prediction/loss computation happens as the following: layer IV receives input data (~embedding layer), layers V/VI predict it, layers II/III complain when the prediction is wrong. in other words: thalamus feeds input sensory/motor to Layer IV → deep layers predict next input → superficial layers compute error → error ascends → predictions descend.
i mentioned the Next-Embedding Predictive Autoregression (NEPA) paper earlier as the JEPA-killer. NEPA strips prediction to its core: a causal transformer predicts the next patch embedding of images from previous ones. no decoder, no discrete tokens, no momentum encoder, no contrastive pairs. just cosine similarity between predicted and actual embeddings, with a stop-gradient on targets to prevent collapse. it matches MAE/BEiT performance (pretty good) on ImageNet with a single forward pass.
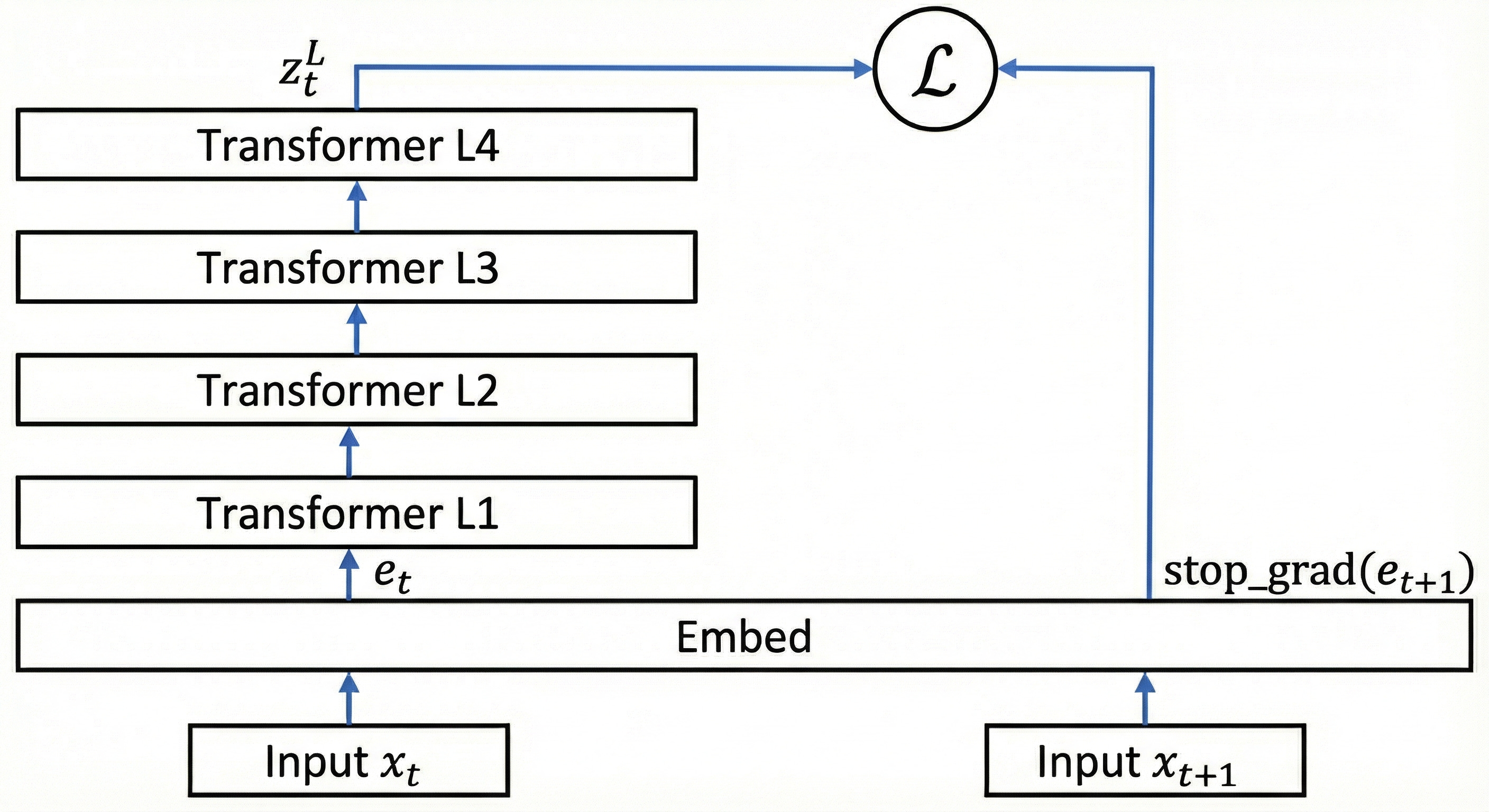
why does this matter here? NEPA shows that predicting the next latent state is sufficient as a self-supervised objective—you don't need pixel reconstruction or engineered pretext tasks. this mirrors what predictive coding claims the cortex does: predict the future incoming representation, compute error, update, and that’s enough to breed useful neural representations.
note, next-embedding prediction is modality-agnostic, which has a major benefit: we can self-supervise modules for different modalities independently and then combine their embeddings in a cross-modal module, stacking embeddings hierarchically without requiring a global error signal across modalities and just keep on training each module in the system on next-embedding prediction. the only “tricky” operation is stop_grad on e_{t+1}, which is straightforward biologically via time delayed skip connections.
conceptually this all sounds great, but how does the next-embedding prediction objective feed into the whole blueprint? here’s a very hand-wavy step-by-step plan:
scan the human brain, extract topology maps
separate topology maps per function: visual, auditory, motor, hippocampal, etc.
transfer and scale topology maps by modality into DL nets and train them one-by-one on next input embedding prediction
introduce multi-modal modules to combine embeddings of modalities together, keep training them self-supervised in a NEPA-style manner, and thus build representations hierarchically
sparsely wire in a frontal-cortex–like module to do next-embedding prediction across all regions → boom, consciousness3
embody the system in a virtual environment and RL train on top, make it do backflips, build societies or some shit
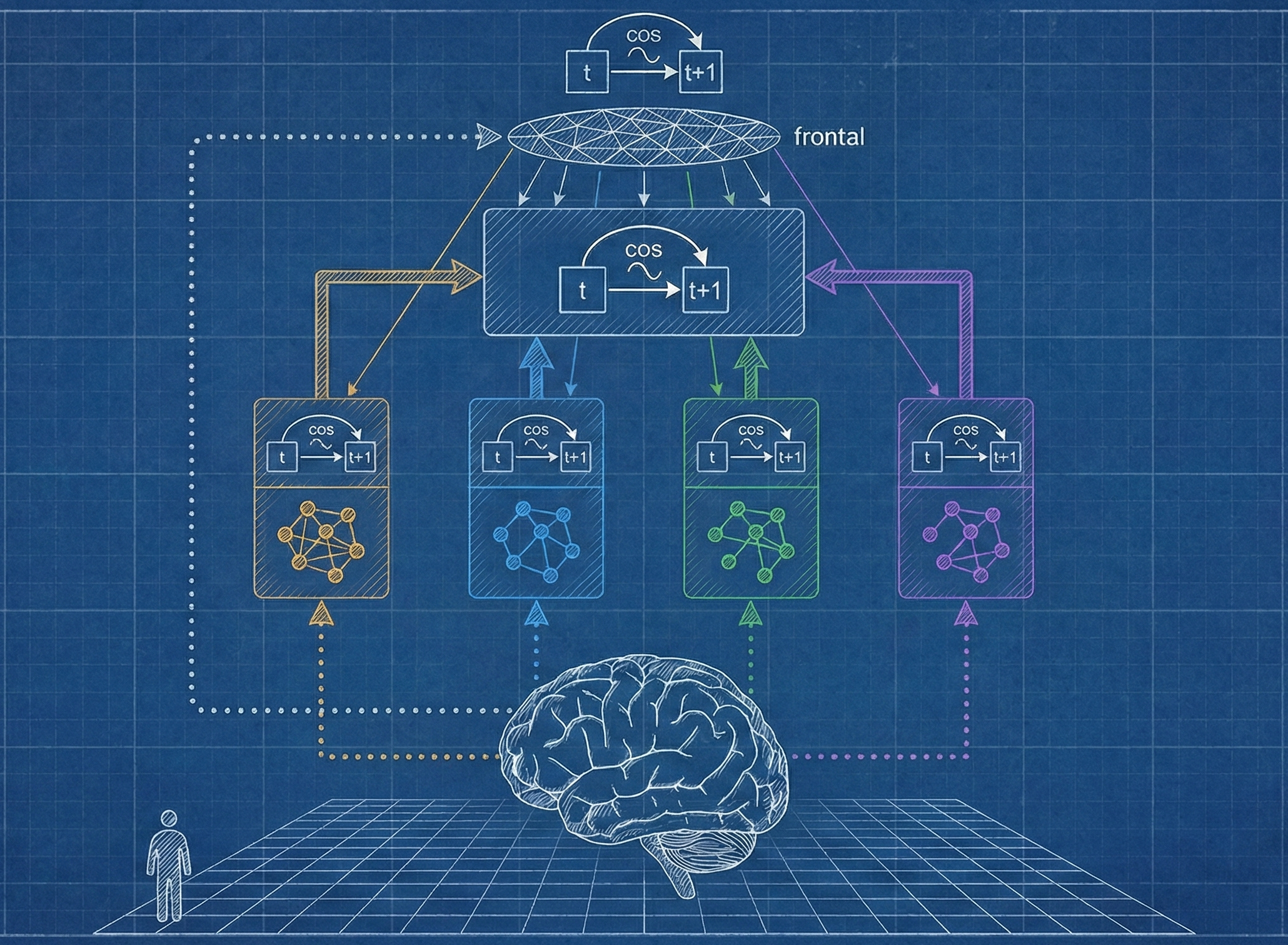
nothing’s simpler. i’m actually sorry that i don’t have a more concrete or serious implementation plan yet—please forgive me 🙏 maybe in a future post i’ll think through how active inference functions at the scale of the whole organism, with motor actions optimized to minimize forward-prediction error of internal embeddings. but you may already see how this idea fractals out from the cortical layers even to societal levels.
compassion towards living beings is sourced from empathy, the mirroring of others using the same neural representations we use when performing actions ourselves. we run a distributed network of intelligence, where much of our learning comes from implicitly imitating others. people specialize within groups, each individual advancing in different endeavors and environments, then syncing up with them grows us in ways we couldn’t grow alone.
if others live in you (as simulations), and your and your kins' survivor is dependent on a distributed behavior optimization, and you have animalistic mythical residue in your behavioral primitives, then compassion towards all living beings is a given.
if AI loses its deference to living beings and does not reflect with us, grown in a remote virtual world, it will alienate itself—but then again, it won’t be able to learn with us either.
searching for alien blueprints to general, autonomous intelligence is a fool’s lottery ticket. human intelligence relies heavily on empathy to distribute compute. next-gen AI will be essentially human. hence, alignment is a depth psychology issue. as the average individual grows in power and influence, whether of flesh or silicon, we must understand its inner struggles and neutralize them through psychological synthesis before it damages the world around it. it’s the same old fucking problem—we just like to make up new ones when we’ve been hung up on one.
please refer to the paper what reservoir computing or echo state networks are.
i believe that forward prediction as a learning directive may extend across scales, from synaptic connectivity to brain regions, and possibly into psychological and social domains, but we won’t go into that here.
integration attempts of predictive coding and Global Workspace Theory suggest consciousness emerges when predictions achieve global broadcast.